
From last week, we showed the hippo demo that we have to our client and faculty. The feedback that we got is to add more elements into the current hippo demo to see if there are any interesting behavior of the RL agent.
We then have a couple design meetings together to talk about what we want to add into the current environment to make the demo more complex. We decided to start from add multiple goals to the hippo, and even think about have the hippo physical structure changes. And we think even further, what if the agent will switch goals during the gameplay or there are other agents with totally different goals. We then come up with 5 different layers of complexity add on top of the basic one. First layer is the base demo we had in week 6.

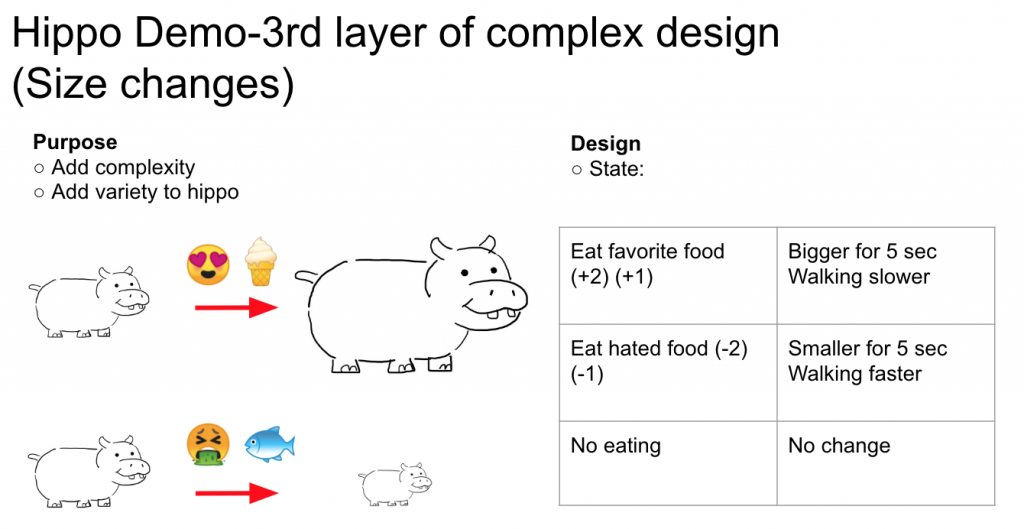
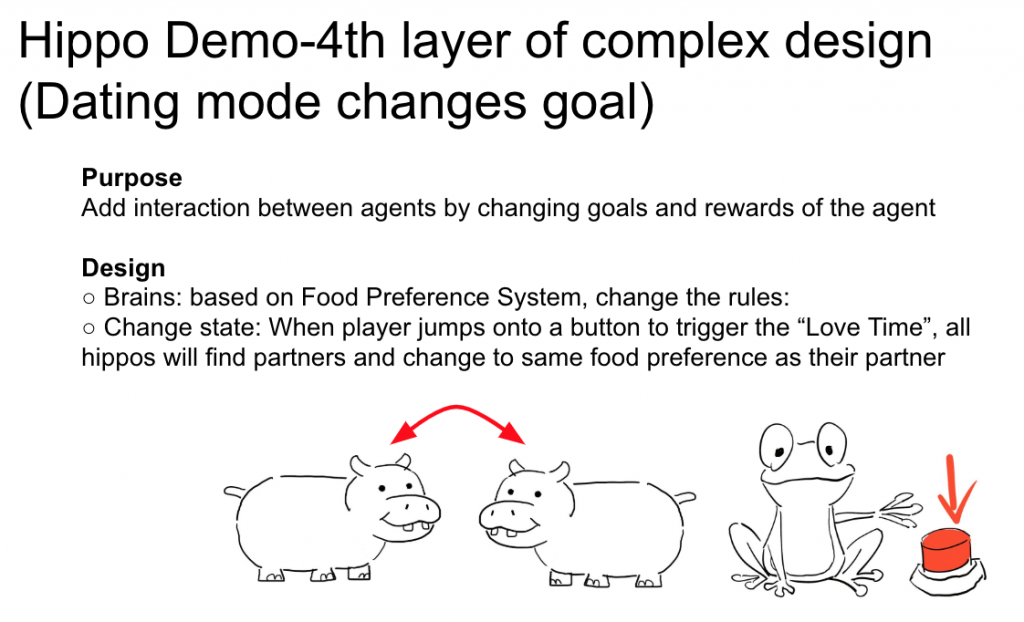
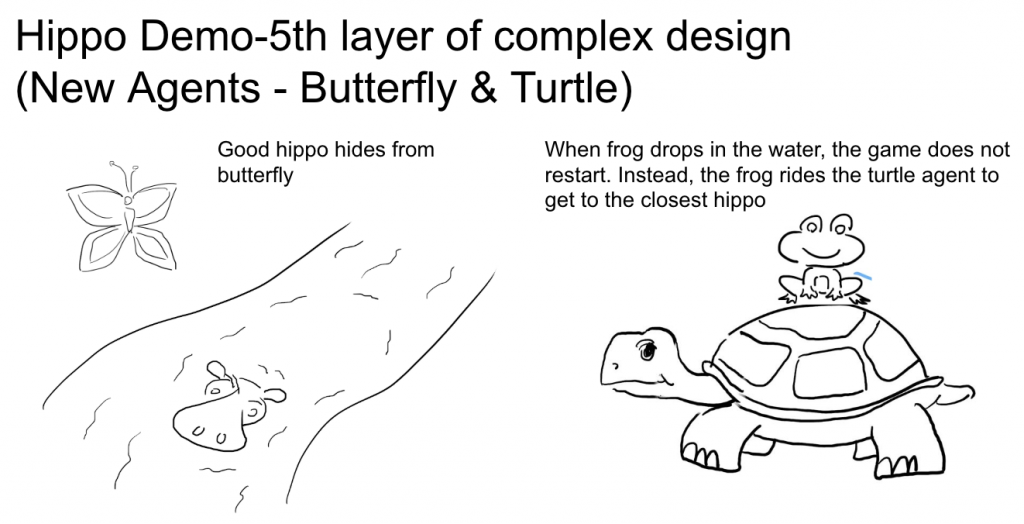
During implementing phase, we encountered some questions like, when the system becomes complicated, it starts to become hard to tune the parameters in order to get the results we want for the RL agent. Also, once there are a new component add into the environment, the system need to be retrained. This is something we will have to think about for the long term.
In our faculty meeting, we again talked about the puzzle game idea from our 6 ideas during quarters. We think that it is still worth spending these 2 weeks to implement a small demo to show it to our client and get some feedback from her. The communication between the agent and the player is a more innovative idea.
We set up a scenario of Imagining a jungle world where you and your friend are roleplaying two birds. You two have to go through a series of stairs to win. However, both of you can only see your partner’s stairs ahead, not yourselves’. You must take turns to jump and rely on your partner to give instructions. You two are allowed to communicate through limited yet creative methods like sending emojis and making sounds.
The agent is trained to respond to player’s behaviors and reactions. The goal is to make it responsive to the dynamic behavior patterns of a player.
It’s unrealistic to have a human player keeps playing the game for a long period of time to train the RL agent. The PlayerAI system is a simulated version of the human player designed to train against the RL system on a reinforcing basis.
To mimic the complexity of player behavior, the PlayerAI is constructed with variables in Movement and Communication based on the game mechanic. Then, by adjusting the parameters for example vision, reaction time, expertise, we generate 3 types of Preference as the input source of RL system.
After showing this demo, Erin has more idea of what we would like to convey before, and she mentioned she would like to see a design documentation of this to think more.
Our client likes both of the ideas, and she thinks that there are both interesting design element and lessons to learn. It will be hard to choose one out of the two ideas, but she encourages us to keep iterating and exploring!
This Friday, we had a field trip to the computer history museum in Mountain View. We spent a nice afternoon learning about the history of computer and different new technologies utilized nowadays. It is a great chance for us to take a bit rest from our halves presentation. One more week from halves, here we go!
