Since the presenter always stand at the same location in front of the audiences, it is harder for him/her to notice those at back then those sitting at the first row. Therefore, we decided to use models with different level of detail based on the sitting positions of the audiences so that the application could spend less time rendering not-so-important stuffs.
The first thing we did is to count down the number of polygons. We deleted the back side of all meshes, and for audience located far from the speaker, we delete their lower body part of meshes:

Left: full body mesh. Right: upper body mesh
We also made set three levels of animation configuration for characters. The first level contains a two-level animator state machine with all animation clips, and also script-driven gazing behavior. Each behavior state (i.e. focused, bored, or chatting) contains a sub-level state machine which includes a number of more subtle animation to provide more realistic / natural looking.
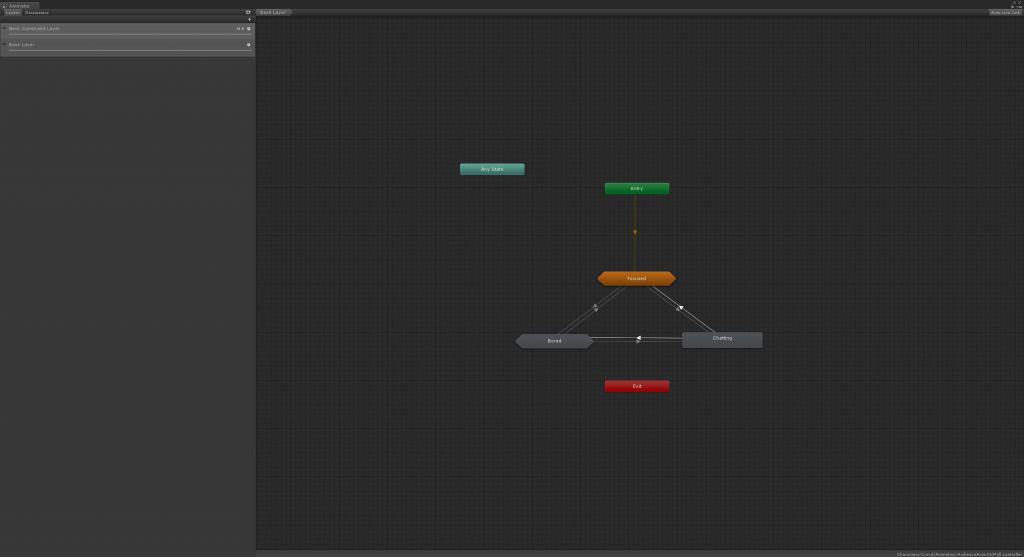
The first level of the two-level state machine
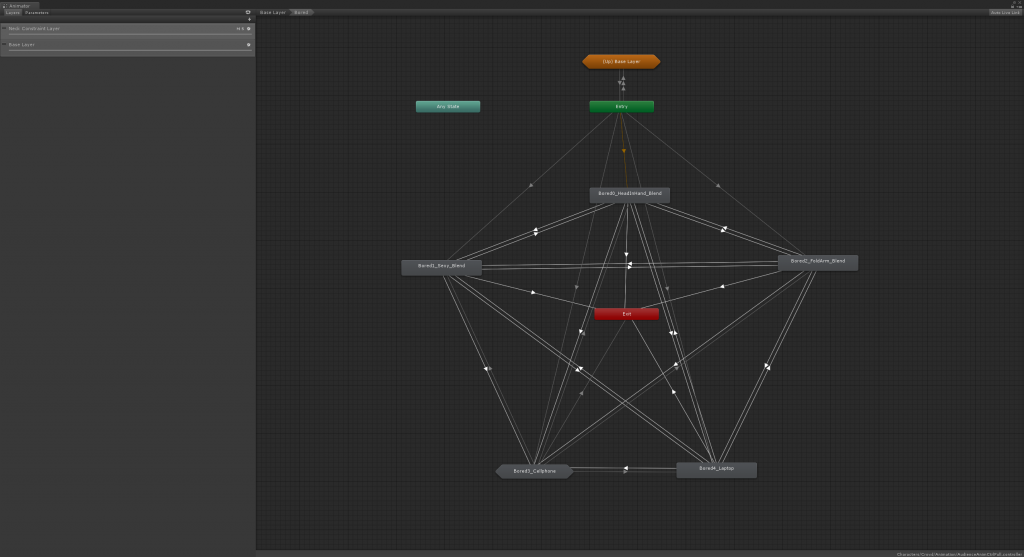
The sub state machine under the bored state
The second level only has a single-level state machine with gazing behavior. The third level, the most simplified one, shares the same single-level state machine, yet even remove the gazing behavior.
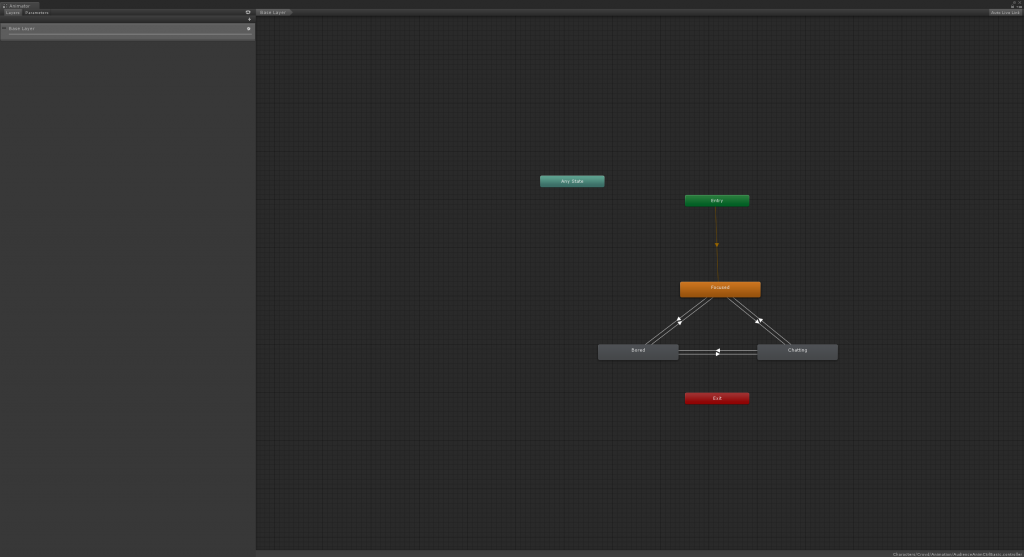
The single-level state machine
Later we found out that the looped animations did not actually add much sense of reality, but occupied much computational power. Therefore we removed those extra frames, and only kept the transitions between different states.