Crowd Simulation is an essential interactive component in VR Rehearsal. Reacting to the speaker’s eye contact and voice fluency, virtual audience improves the immersion of the virtual reality experience, and provide real-time feedback to the speaker. Simulating human behavior is no easy job, and our goal is not to produce super realistic behavior, but to create the virtual audience that are first responsive to the speaker, and then behave naturally in some reasonable level. And also, we do not want to spend all the computational power on it.
The method we used is a simple state machine-based individual model. For each individual, the top of the hierarchy are three main states: focused, bored, and chatting. Under those three main states, more subtle states with poses/animations are defined, such as playing cellphone, sleeping, crossing legs. At each time step, the individual receives the speaker’s input, as well as other global / constant factors, including elapsed time or seat position. Each state would calculate its weight / probability based on those factors. To determine which state would be selected as the next state, we sample from the state probability mass function. Finally, the individual is switched to a new state to behave differently. The process is illustrated by the following flow chart.
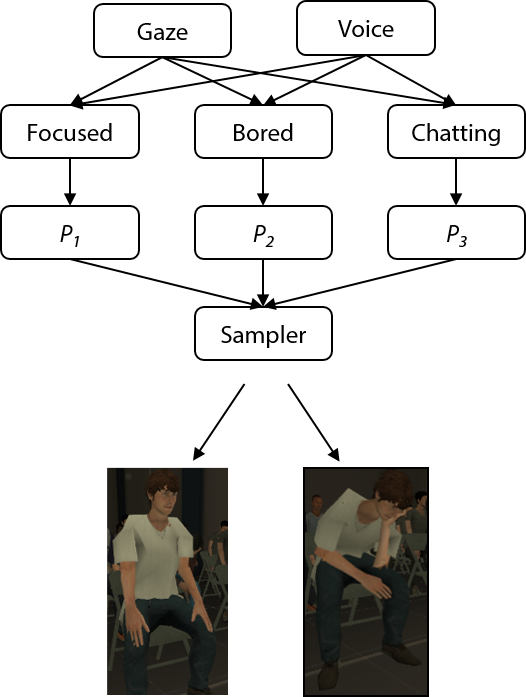
Crowd simulation: the process
To test the system thoroughly, the simulator is designed to be modularized. The simulator consists of five layers as showed in the following picture. The final simulation output is a composite of separated intermediate results.
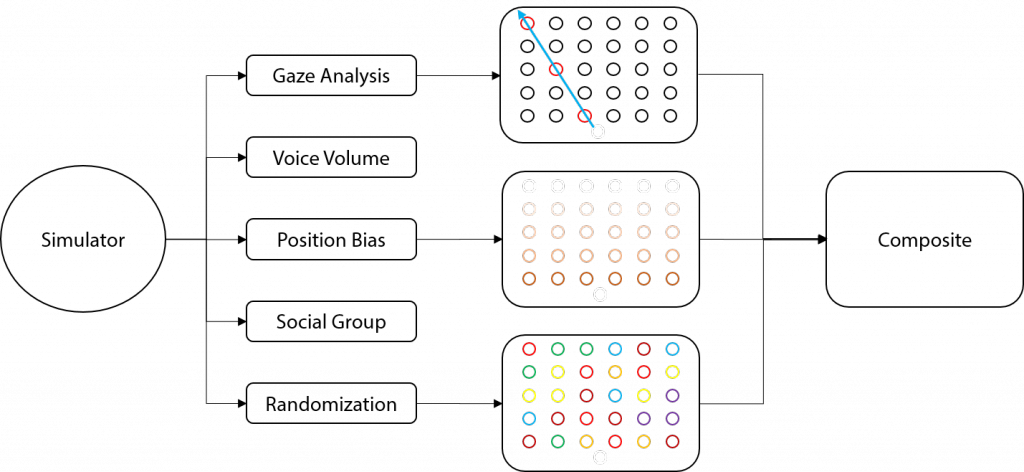
Decouple complex system into modules
The fact that the behavior is based on state machine results in the discontinuous artifact of individual behavior. We tried to mitigate the problem by randomization and blending between state animations. Since the system is updated by fixed time step, virtual audience is not responsive enough to “sudden” events such as sudden eye contact. Therefore, we modified the system by setting two update cycles with different frequencies instead of one. The faster update cycle handles the frequent change from the speaker, and the slower cycles handles the internal (gradual) changes.