Hi all, this is Chris Sun from team VR Rehearsal. Oral activity is an important factor which VR Rehearsal looks into to assess user’s fluency of speech, and based on it, defines the behavior of virtual audiences.
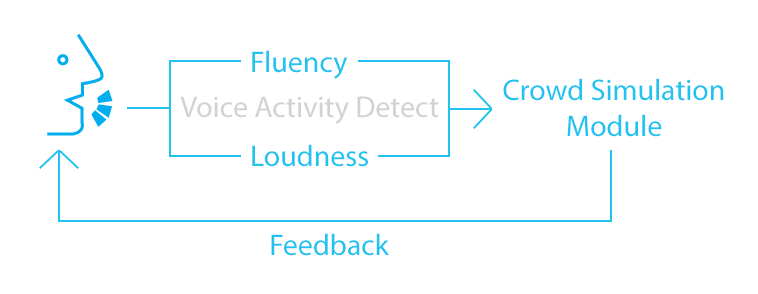
To detect oral activity, i.e. whether the user is speaking or not, we look into the audio data the application recorded every frame. We rely on a volume threshold to determine if some voice activity takes place in this frame.
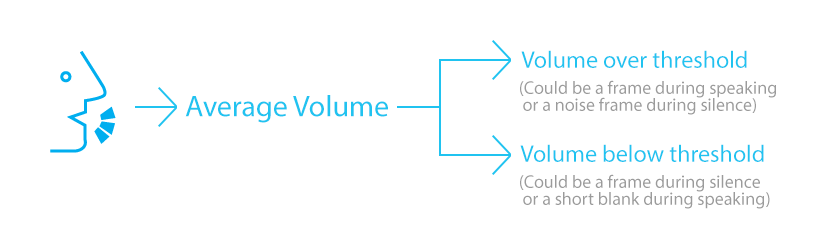
Based on this, how could we further determine if the user is speaking or not? A frame of decent high volume could be an irrelevant noise during a silent interval, while a frame of decent low volume could be regular blanks between words.
The trick to deal with this is taking one step away from “one frame” but looking at the whole thing in a series of frame and concentrate on “state change” rather than the state of a single frame. We first define a “current state” of the user: the user could be either speaking or not, never both.
Then, when a frame of the opposite activity appears, we add the time of this frame to a timer; the timer shows how long the user has “suspiciously” been on the other state, and, if that’s enough long, we determine that the state of the user has changed.
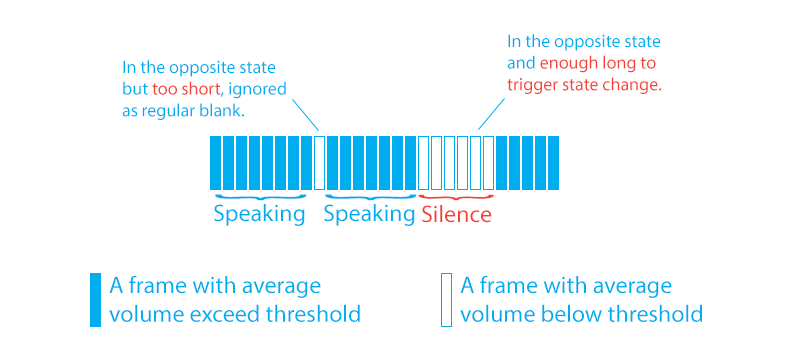
If, when a frame of the current state appears, the “opposite state” has not stay for enough long, then we assume the suspicious “opposite state” is a noise and discard it.
The final trick will be widely performing tests and finding the best volume threshold and state transition threshold for the algorithm.