
Week 3: Let’s look at the tech

Like mentioned in the last post, Ako explored both the passthrough AR and speech processing technologies last week. We did some prototyping, some vetting and, finally, settled on the design decisions to fit the tech. This was to make sure that we spend our next weeks focussing on the core essence of our project, which is to create a smooth conversational experience for the player and not worry about implementing the technology itself.
Here, we focus on the two main technical aspects that are our pillars over which this project is built upon.
The AR Part
The reason we use AR is for the player to be aware of the outside world so that they can interact with the physical game objects while also being able to view virtual content. Our experience involved one main virtual character – the agent and other help content depending on the game pieces on the table.
Thus, we are now looking at a feature that could track game states and pieces throughout the experience to provide interactive advice and guidance. The headset we are using will be expected to get the input video feed and process the items in the scene. We tried the following combinations:
HoloLens + Vuforia:
Pros:
- Official Vuforia Support
- Wireless
Cons:
- Small – field of view
- Low battery life
- Cannot live stream when using Vuforia
Zed Camera + Vuforia:
Not supported due to the stereo nature of the video feed from the Zed Camera.
Zed Camera + ArUco Markers
Pros:
- Relatively smooth tracking
- Proved compatibility
- Versatile for design
Cons:
- Need to think about players outside of the headset
- Important to rely on the stability of augmented content
Thus, we have decided to move forward with the Zed Camera attached to an Oculus Rift and uses ArUco markers to track the game pieces.
Planned AR Pipeline
![]()

![]()

![]()

The Conversation Part
Conversation with the AR character is our most important mode of interaction between the player and the application. Therefore, speech recognition and processing is our other core feature.
Here is a portion interaction chart defining how the interaction between the agent and the player from our week’s weeks blog post.

As we can see, the agent gets both asked questions and answers questions.
Thus, we need a 3-step system that can convert Speech to Text, process it and convert the processed data into speech. We make use of multiple available APIs to achieve this.
Step 1: Google Cloud Speech – Speech to Text
We are really inclined to use Google Cloud Speech API to convert our users’ input into text which can later be processed by the “brain” of our program to give a corresponding response. We use the Unity Lowkey Parser project to integrate this into a Unity project.
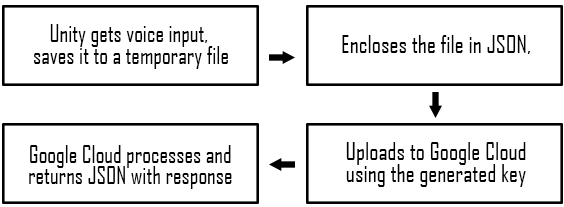
We loved it for many reasons, one being that it was able to understand multiple English accents. It is a cloud platform that uses neural networks and hence continuously learns from every user that uses these services in the world.
Step 2: Dialogflow for response interpretation
Now that we have a text form of the spoken input, we need to process it and give back an appropriate response. This processing is managed by a Google service called Dialogflow. Dialogflow contains a Language Understanding Model that is capable of taking in the given text dialog and interpret it based on the configurations it is set to. The configurations also contain the set responses that need to be returned in every case.
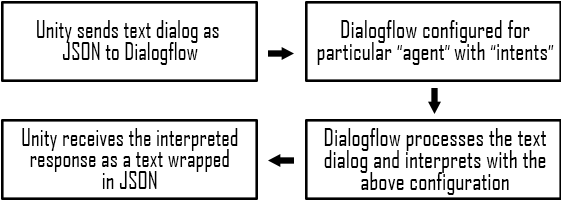
Step 3: Convert Response to Speech
Finally, the character needs to speak out the interpreted response to the player. We first tried the IBM Watson to convert the text into speech. The text response wrapped as a JSON in the previous step is unwrapped and converted to SSML (Speech Synthesis Markup Language), a standard markup language for synthetic speech applications. IBM Watson is capable of reading this markup and converting it to an audio clip which gets streamed into Unity.

One major caveat with IBM Watson has been that it contains only one voice – Allison, which replicates the tone and accent of a female American speaker. We feel that this voice wouldn’t be as dyanamic or suited for the kind of character design we are looking at. Therefore, we are plannig to try a much newer (and hence, less documented) text to sound API owned by Amazon, called Amazon Polly which also leverages its cloud AWS services.
Preparing for Quarters
We are also one week away from Quarters Open House. We have also been preparing ideas, plans and demos to show during quarters. We are also in the process of finalizing our branding materials (posters, half-sheets, and logos) this week!


Recent Comments